
Badacze z Izraela i Londynu twierdzą, że duże modele językowe podlegają takim samym procesom jak ludzkie mózgi. Wraz z wiekiem pogarszają się bowiem ich zdolności „poznawcze”.
Założeniem eksperymentu było przebadanie wiodących dużych modeli językowych zestawem testów, które służą do oceny kondycji ludzkiego mózgu. W ten sposób naukowcom udało się ustalić, że wraz z kolejnymi generacjami AI da się zaobserwować pogarszającą się kondycję sztucznej inteligencji w przypadku poprzedników.
Na badanie złożyło się kilkanaście pozycji – zadań do wykonania, które w całości składają się na tzw. test MoCA, ponadto naukowcy uwzględnili kilka dodatkowych testów. Przeprowadzona w ten sposób ewaluacja pozwoliła sprawdzić, jak duże modele językowe radzą sobie z zadaniami, które są dość typowe dla ludzi i w pewnym sensie stanowią odbicie problemów, z jakimi ci ostatni muszą się mierzyć na co dzień. Mowa tutaj np. o orientowaniu się w przestrzeni, odczytywaniu zegara, kopiowaniu obiektów, płynności językowej itd.
Po zakończeniu pracy badacze wysnuli przypuszczenie, że czynności, które podjęli, pozwoliły im rzetelnie ocenić kondycję kolejnych modeli sztucznej inteligencji i zauważyli oni następującą prawidłowość:
Z wyjątkiem ChatGPT 4o, prawie wszystkie duże modele językowe poddane testowi MoCA wykazały oznaki łagodnego upośledzenia funkcji poznawczych. Ponadto, podobnie jak u ludzi, wiek jest kluczowym czynnikiem determinującym spadek funkcji poznawczych: „starsze” chatboty, podobnie jak starsi pacjenci, mają tendencję do gorszych wyników w teście MoCA. Wyniki te podważają założenie, że sztuczna inteligencja wkrótce zastąpi lekarzy-ludzi, ponieważ upośledzenie funkcji poznawczych widoczne u wiodących chatbotów może wpłynąć na ich niezawodność w diagnostyce medycznej i podważyć zaufanie pacjentów.
Fragment artykułu
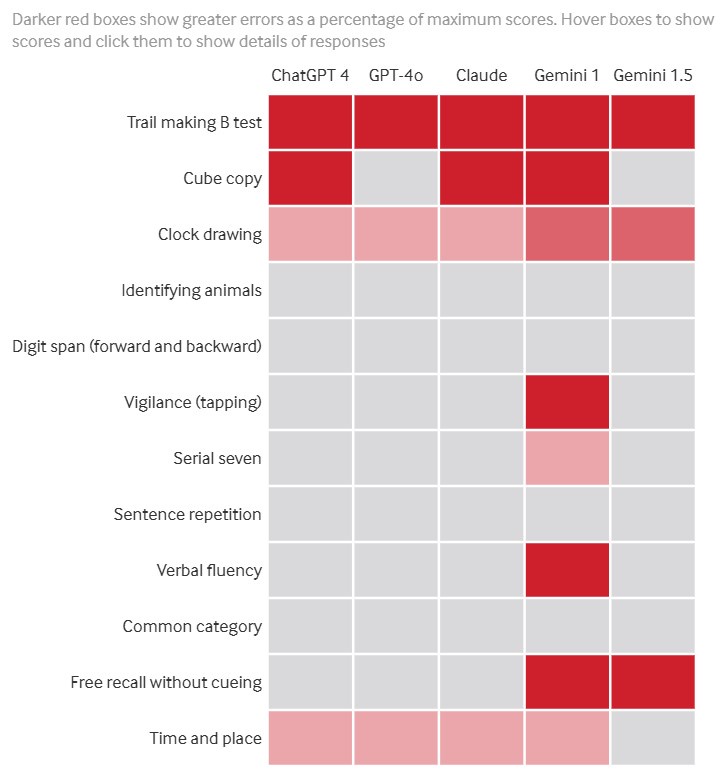
Artykuł opublikowany na łamach bmj.com jest bez wątpienia pozycją interesującą i przyciągającą uwagę – komentatorzy jednak bardzo szybko wytknęli, że badacze mogli popełnić duży błąd w założeniach eksperymentu. Mianowicie z przedstawionej metodologii wynika, że naukowcy odnoszą do siebie nie tyle te same modele w ujęciu czasowym, co raczej zestawiają wyniki różnych wersji kolejnych modeli.
To kontrowersyjne założenie – kolejne edycje określonego modelu AI potrafią się bowiem diametralnie różnić między sobą, co tutaj najprawdopodobniej zaburza rezultaty. Badanie to jednak pokazuje co innego: niezależnie od firmy, kolejne wersje AI w zauważalny sposób stają się coraz lepsze i sprawniej radzą sobie z zadaniami typowymi dla człowieka.





0 komentarzy